Finding duplicated files using command line CLI in Linux MacOS Ubuntu
Easy way to find duplicated files in a folder or in all disk
find . -type f -name "*" -print0 | xargs -0 -I {} shasum -a 256 {}
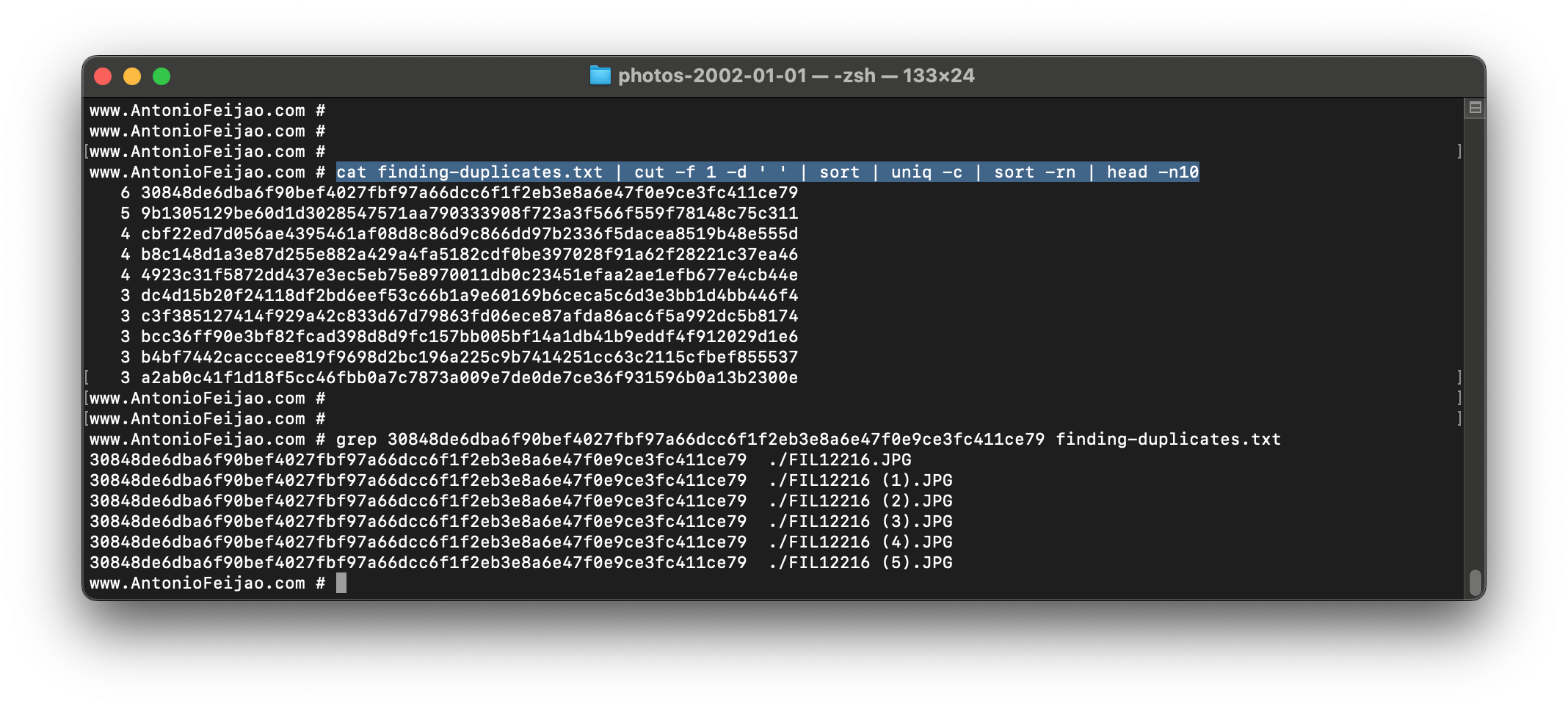
Or course, output the above command to a file, cut -f 1, then sort and pipe it into uniq -c to count duplicates
find . -type f -name "*.JPG" -print0 | xargs -0 -I {} shasum -a 256 {} > finding-duplicates.txt
cat finding-duplicates.txt | cut -f 1 -d ' ' | sort | uniq -c | sort -rn | head -n10
grep 30848de6dba6f90bef4027fbf97a66dcc6f1f2eb3e8a6e47f0e9ce3fc411ce79 finding-duplicates.txt
of course, we now can automate this to keep the first file but move the duplicated into a backup folder before deleting them.
Example of my output on a folder with old photos that got duplicated over type... some photo is now 6x duplicated... time to automate tidying up!
Happy learning,
Antonio Feijao